Update: 15 January 2019
The combination of a CPU with a GPU can deliver the best value of system performance, price, and power. In will post we will implement the OpenCL capabilities on our Raspberry Pi’s VideoCore IV GPU through VC4CL library, enabling us to exploit the Raspberry Pi’s GPU that will allow a broader class of computationally intensive programs to run on this energy-efficient platform. Introduction
The Central Processing Unit(CPU) has often been called the brains of the PC. But increasingly, that brain is being enhanced by another part of the PC – the GPU (Graphics Processing Unit), which is its soul. Modern processor architectures have embraced parallelism as an important pathway to increased performance. Facing technical challenges with higher clock speeds in a fixed power envelope, Graphics Processing Units (GPUs) have become important in providing processing power for high-performance computing applications, giving software developers portable and efficient access to the power of these heterogeneous processing platforms.
The use of GPGPUs(parallel programming setup involving both GPUs & CPUs) for scientific computing started some time back in 2001 with the implementation of Matrix multiplication. One of the first common algorithm to be implemented on GPU in a faster manner was LU factorization in 2005. But, at this time researchers had to code every algorithm on a GPU and had to understand low-level graphic processing. In 2006, Nvidia came out with a high-level language CUDA, which helps you write programs from graphics processors in a high-level language. This was probably one of the most significant changes in the way researchers interacted with GPUs Use Cases:
This are the normal cases where you should use GPUs for computation:
- Fast Permutation: Devices moves memory faster than Host
- Data Translation: Change from one format to another
- Numerical Acceleration: Devices calculate faster than Host big chunks of data
In today’s world, the GPU can now take on many multimedia tasks, such as accelerating video, transcoding (translating) video between different formats, virus pattern matching and really hard problems to solve are those that have an inherent parallel nature – video processing, signal processing and most important them of all Deep Learning(DL) applications.
Types of GPU Interfaces:
CUDA and OpenCL are two interfaces for GPU computing, both presenting similar features but through different programming interfaces. CUDA is a proprietary API and set of language extensions that work only on NVIDIA’s GPUs. OpenCL, by the Khronos Group, is an open standard for parallel programming using Central Processing Units (CPUs), GPUs, Digital Signal Processors (DSPs), and other types of processors. CUDA and OpenCL offer two different interfaces for programming GPUs. OpenCL is an open standard that can be used to program CPUs, GPUs, and other devices from different vendors, while CUDA is specific to NVIDIA GPUs.
OpenCL:
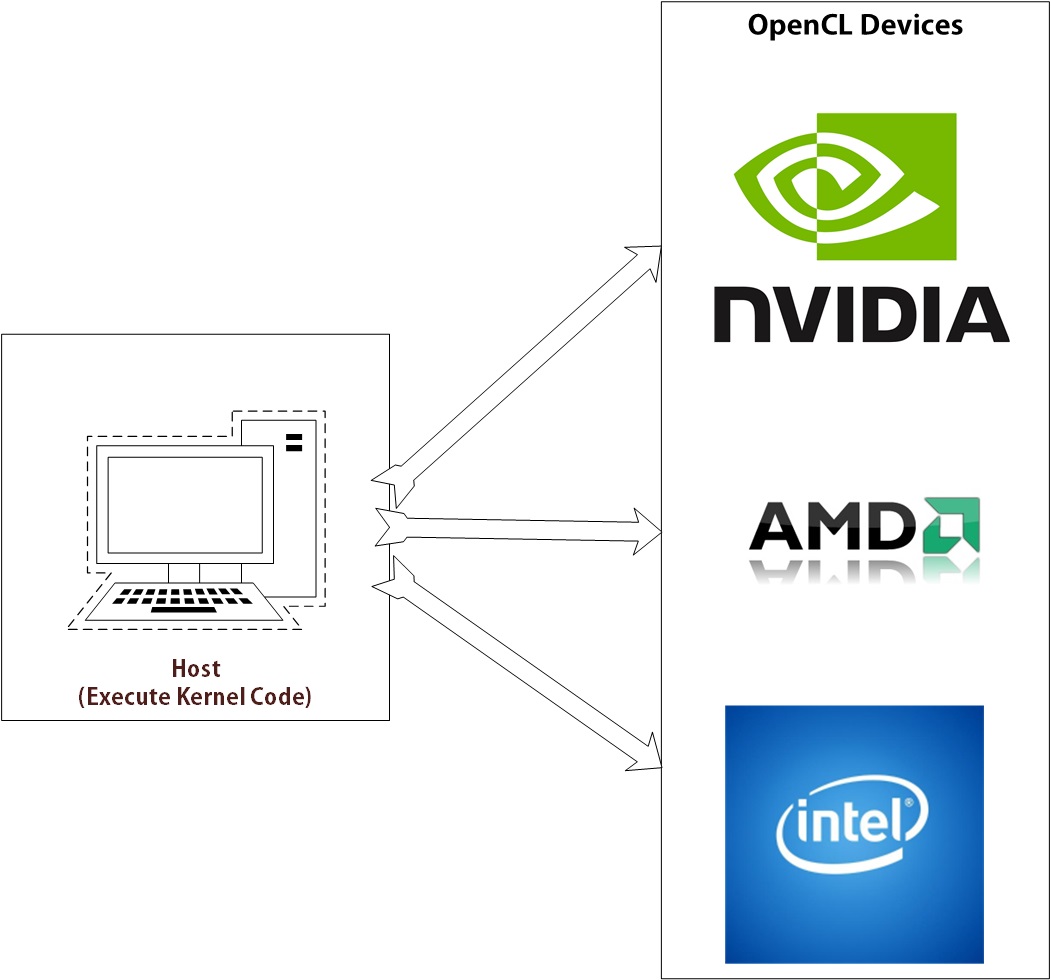 Host System interaction with various OpenCL Devices(GPUs)
Host System interaction with various OpenCL Devices(GPUs)
OpenCL (Open Computing Language) is a framework for GPU programming, capable of targeting very dissimilar parallel processing devices. They consist for example of CPUs GPUs DSPs and FPGAs. OpenCL is particularly suited to play an increasingly significant role in emerging interactive graphics applications that combine general parallel compute algorithms with graphics rendering pipelines.
OpenCL API:
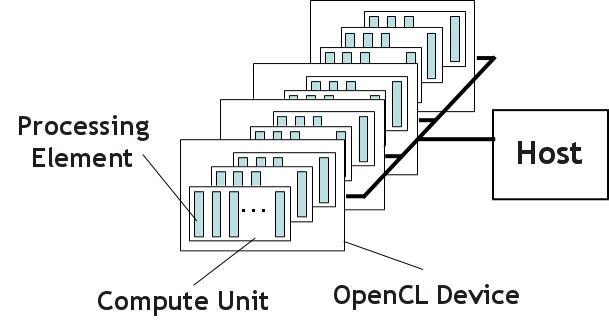
Host: Your desktop system Compute Device: CPU, GPU, FPGA, DSP. Compute Unit: Number of cores Processing Elements: ALUs on each core.
OpenCL consists of an applications programming interface (API) for coordinating parallel computation across heterogeneous processors and a cross-platform programming language with a well-specified computation environment. Using the core language and correctly following the specification, any program designed for one vendor can execute on another’s hardware. The model set forth by OpenCL creates portable, vendor- and device-independent programs that are capable of being accelerated on many different hardware platforms. The OpenCL API is a C with a CppWrapper API that is defined in terms of the C API. It also provides third-party bindings for many languages, including Java, Python, and .NET. OpenCL gives a set of functions to control devices on your system.
The Host Device does not know what to do, the OpenCL-API control the whole system systematically. Below, we have the major components of the Host OpenCL-API:
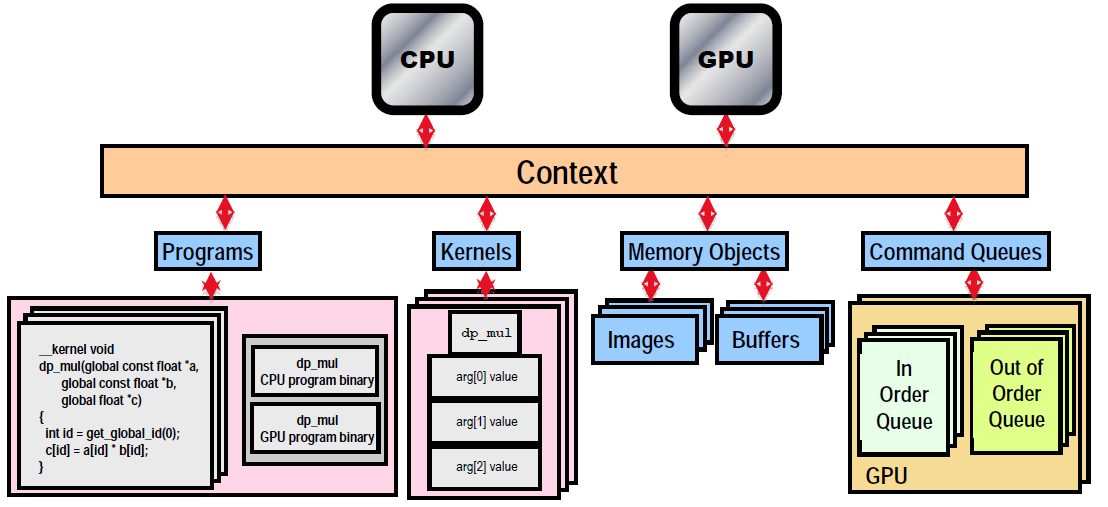
- Platform
- Context
- Programs
- Asynchronous Device calls
The OpenCL standard:
- Supports both data- and task-based parallel programming models
- Utilizes a subset of ISO C99 with extensions for parallelism
- Defines consistent numerical requirements based on IEEE 754
- Defines a configuration profile for handheld and embedded devices
- Efficiently interoperates with OpenGL, OpenGL ES, and other graphics APIs
OpenCL Kernels:
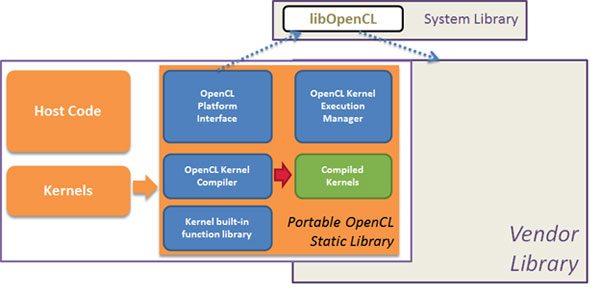
Kernels are the parts of an OpenCL program that actually execute on a device. The OpenCL API enables an application to create a context for management of the execution of OpenCL commands, including those describing the movement of data between the host and OpenCL memory structures and the execution of kernel code that processes this data to perform some meaningful task. Unlike a CUDA kernel, an OpenCL kernel can be compiled at runtime, which would add to an OpenCL’s running time. On the other hand, this just-in-time compile may allow the compiler to generate code that makes better use of the target GPU. On OpenCL the devices will execute kernels, those kernels are small functions written in OpenCL C which is a C (C99) subset. Kernels are an entry point (like the main function) for a device execution. The kernels are loaded and prepared by the Host.
Here are the main differences between C and OpenCL C:
- No function pointers
- No recursion
- Has vector types
- Has image types
- Allow structures but kill performance, and communication with host could be complicated.
- There is no mechanism for different kernels to cooperate.
Raspberry Pi GPU Hardware:

Raspberry Pi(RPI) is equipped with a relatively strong and inexpensive CPU and GPU is quite popular for numerous embedded applications owing to both its low price and low power consumption in comparison to its capabilities. The Raspberry Pi GPU is a Broadcom VideoCore IV system, providing enhanced scalability by using multiple floating-point shader processors called QPUs. The Video Core IV provides four QPUs, each of which is a 16-way SIMD processor. Each processor has two vector floating-point ALUs that can execute multiple mathematical operations in parallel in a single cycle. It can reach 24 GFLOPs in computational throughput. In addition, GPU rendering often referred to as hardware rendering, is much faster than software rendering. As a result, graphics-intensive applications (like FFmpeg) would typically prefer GPU rendering. That makes it essential to know how to best utilize the GPU on RPI.
VC4CL
VC4CL(VideoCore IV OpenCL) is an implementation of the OpenCL 1.2 standard exclusively for Raspberry Pi’s VideoCore IV GPU. VC4CL implements OpenCL 1.2 for the VideoCore 4 graphics processor albeit the EMBEDDED PROFILE of the OpenCL-standard, which is a trimmed version of the default FULL PROFILE. This implementation does support the OpenCL ICD concept for dealing nicely with most Linux systems.
VC4CL implementation consists of:
- The VC4CL OpenCL runtime library, running on the host CPU to compile, run and interact with OpenCL kernels.
- The VC4C compiler, converting OpenCL kernels into machine code. This compiler also provides an implementation of the OpenCL built-in functions.
- The VC4CLStdLib, the platform-specific implementation of the OpenCL C standard library, is linked in with the kernel by VC4C OpenCL-Support The VC4CL implementation supports the EMBEDDED PROFILE of the OpenCL standard version 1.2. Additionally, the cl_khr_icd extension is supported, to allow VC4CL to be found by an installable client driver loader (ICD). This enables VC4CL to be used in parallel with another OpenCL implementation, e.g. pocl, which executes OpenCL code on the host CPU. A piece of more extensive information regarding VC4CL library can be found here.
VC4CL Library Installation for Raspbian:
In this section, we will learn how to install & validate VC4CL build on Raspbian. But before we proceed, here are some important considerations for this post:
Important points:
- We will be using the specific commit clones of VC4CL libraries from my git repo. for this post to avoid any dependency problem, but you can always check out the latest source here.
- The post will build the libraries from scratch for maximum compatibility but you can find easy to install Nightly builds and Latest Releases(Not implemented yet) Debian package here.
- Also kudos to @doe300 for bringing up this project.
Note: VC4CL can emulate all V3D register and mailbox system-call access to allow emulating of the full VC4CL runtime on any host machine in the latest update, be sure to check that out too. (Not implemented here)
VC4CL installation
- Install major runtime dependencies and do necessary upgrades:
1 2 3
sudo apt update sudo apt upgrade sudo apt install build-essential git llvm clang clang-format libclang-dev libbsd0 libc6 libedit2 libffi6 libgcc1 libllvm libncurses5 libstdc++6 libtinfo5 zlib1g llvm-dev ocl-icd-opencl-dev ocl-icd-dev opencl-headers clinfo
- VC4CL requires VC4C Compiler to compile OpenCL C-code. This compiler supports OpenCL C (via LLVM or SPIRV-LLVM), LLVM-IR and SPIR-V code, depending on the build configuration. We also require VC4CLStdLib that contains the VC4CL implementation of the OpenCL standard-library and is required to build the VC4C compiler. Therefore we are going to clone the mentioned three Github repositories into our new folder.
1 2 3 4
mkdir work && cd work git clone https://github.com/abhiTronix/VC4CL.git git clone https://github.com/abhiTronix/VC4C.git git clone https://github.com/abhiTronix/VC4CLStdLib.git
- First, we build & install the VC4CLStdLib:
Note: -DBUILD_DEB_PACKAGE build option can be used to build .deb package for future use if required.
1 2 3 4
cd VC4CLStdLib cmake -DCMAKE_INSTALL_PREFIX=/usr -DBUILD_DEBUG=OFF -DCROSS_COMPILE=OFF -DBUILD_DEB_PACKAGE=OFF . sudo make sudo make install
- Secondly, we can now proceed to build & install the VC4C compiler:
Note: Cmake builds options are kept at minimal configuration. Any advanced build usage can be determined here.
1
2
3
4
5
cd VC4C
cmake -DCMAKE_INSTALL_PREFIX=/usr -DBUILD_DEBUG=OFF -DBUILD_DEB_PACKAGE=OFF .
sudo make
sudo make install
sudo ldconfig
- Finally, we can now install the VC4CL OpenCL Library:
Note: Cmake builds options are kept at minimal configuration. Any advanced build usage can be determined here.
1
2
3
4
cd VC4CL
cmake -DCMAKE_INSTALL_PREFIX=/usr -DBUILD_DEBUG=OFF -DBUILD_DEB_PACKAGE=OFF -DBUILD_ICD=ON -DIMAGE_SUPPORT=ON .
sudo make
sudo make install
Validate VC4CL installation
The program clinfo can be used to test, whether the ICD loader finds the VC4CL implementation.
1
sudo clinfo
Note: Because of the DMA-interface which has no MMU between the GPU and the RAM, code executed on the GPU can access any part of the main memory! This means an OpenCL kernel could be used to read sensitive data or write into kernel memory! Therefore, any program using the VC4CL implementation must be run as root!
If the VC4CL is successfully installed the output will look something like this.
VC4CL implementation clinfo output on Raspberry Pi Terminal
VC4CL: Parallel Computing with Parallel Programming
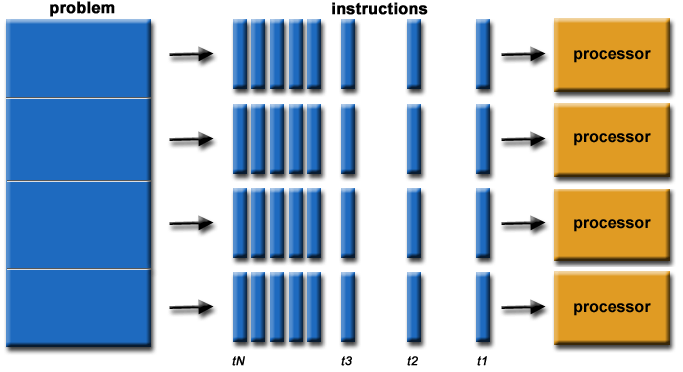 Parallel Computing
Parallel Computing
With OpenCL, the goal is often to represent parallelism programmatically at the finest granularity possible. OpenCL provides a standard interface for parallel computing using task- and data-based parallelism. This feature makes OpenCL ideal to solve the complex computational problem by utilizing multiple compute resources. Here is an example:
Note: Some of VC4CL inbuilt methods/functions are still experimental/Not Supported, Please check out their wiki here.
1d Vector addition
For instance, imagine a function that needs to calculate the addition of two 1d Vectors of size 10.000000 (10 million elements). On normal programming this would be something like:
1
2
3
4
5
6
7
8
9
void vectorAdd( float *a, float *b, float *c, int numElements)
{
int nIndex = 0;
for (nIndex = 0; nIndex < numElements; nIndex++)
{
// This will execute 10.000000 times one after the other.
c[nIndex] = a[nIndex] + b[nIndex];
}
}
On OpenCL Kernels we have the option to execute this function on multiple processing elements. Ideally, you could have one processing element for each vector element. In this case, the whole operation would take 1 cycle.
1
2
3
4
5
6
__kernel void vectorAdd(__global const float * a,__global const float * b,__global float * c)
{
// Vector index
int nIndex = get_global_id(0);
c[nIndex] = a[nIndex] + b[nIndex];
}
The truth is that frequently you have less processing elements than elements to work with. Observe that we want to substitute the for-loops by the parallel execution of multiple iterations of the previous loop. Current Shortcomings of VC4CL:
The project is being actively developed but still, it currently lacks some of the OpenCL features like:
Note: These shortcomings may or may not exist in future updates, be sure to check out the Latest commits in Official VC4CL Github Repo.
- 4-bit data-types (long and double via cl_khr_fp64) are limitedly supported since the VideoCore IV GPU only provides 32-bit instructions.
- The cl_khr_fp16 half and double floating-point type are also not supported.
- Images and any associated feature (e.g. samplers) are not supported
- Other Application specific Limitations are discussed here.
Conclusion:
In this post we successfully implemented OpenCL on our Raspberry Pi’s VideoCore IV GPU, using VC4CL library and discussed its various aspects. That’s all for now, We will utilize these VC4CL’s parallel computing capabilities for optimizing OpenCV and Other Deep Learning applications on Raspberry Pi in the upcoming posts. Hope you enjoyed the post.